(Cross-posted from my website.)
This is the video and transcript for a ~45-minutes talk I gave in February 2024 about my report “Scheming AIs: Will AIs fake alignment during training in order to get power?” (slides available here). See also this podcast for a more conversational overview of similar content.
Main talk

Okay, hi everybody. Thanks for coming. So this talk is about whether advanced AIs will fake alignment during training in order to get power later. This is a behavior that I'm calling scheming, it's also often called deceptive alignment.
Preliminaries

So I'm going to start with a few preliminaries.
As was mentioned, this talk is based on a public report called Scheming AIs available on arXiv. There's also an audio version on my podcast, Joe Carlsmith Audio, if you prefer that. So I encourage you to check that out. I'm going to try to cover many of the main points here, but the report is pretty long and so I'm not going to go into that much depth on any given point. So if you want more depth or you have burning objections or clarifications or you want to work on it, I encourage you to check out the full report.
Second, I'm going to assume familiarity with:
- The basic argument for existential risk from misaligned AI. That is roughly the thought that advanced AI agents with goals that conflict with human goals would have instrumental incentives to seek power over humans, and potentially to disempower humanity entirely, an event I'll call takeover, AI takeover. If that story didn't sound familiar to you, I do have some other work on this topic which I would encourage you to check out. But some of the talk itself might make a little less sense, so I apologize for that.
- I’m also going to assume familiarity with a basic picture of how contemporary machine learning works. So very roughly, imagine models with lots of parameters that are being updated via stochastic gradient descent (SGD), such that they perform better according to some feedback signal. And in particular, I'm often going to be imagining a default baseline training process that resembles somewhat what happens with current language models. Namely, a pre-training phase in which a model is trained on some combination of internet text and potentially other data. And then a fine-tuning phase, in which it's trained via some combination of maybe imitation learning or reinforcement learning. So that's the baseline picture I'm going to be imagining. There are other paradigms in which questions about scheming will arise, but I'm going to focus on this one.
I'm also going to condition on the AIs I discuss being “goal directed”. And what I mean by that is that these AIs are well understood and well predicted by thinking of them as making plans on the basis of models of the world in pursuit of objectives. This is not an innocuous assumption. And in fact I think confusions in this vicinity are one of my most salient candidates for how the AI alignment discourse as a whole might be substantially off base. But I want to set aside some questions about whether AIs are well understood as goal directed at all, from questions about conditional on them being goal directed, whether they will be schemers. So if your objection to scheming is, "I don't think AIs will have goals at all.”, then that’s a perfectly fine objection, especially in particular training paradigms, but it's not the objection I'm going to focus on here. And I also do have in the other work, on misalignment in general, some thoughts about why we might expect goal directness of this kind. In particular, I think goal directness is useful for many tasks.
Finally, I want to flag that in addition to potentially posing existential risks to humanity, the sorts of AIs I'm going to be discussing I think are disturbingly plausible candidates for moral patients in their own right. And so for simplicity, I'm going to mostly set this issue aside, but I think it raises a number of quite uncomfortable questions that I think are real and relevant and that are coming at us very fast. We sort of talk in a lot of alignment context as though AIs are such that you can do whatever you want to them in pursuit of your own ends. But I think if they're moral patients, that's not the case and importantly not the case. And I think we should notice very hard if we keep saying, "By the way, maybe they are moral patients, but we're going to ignore that for now." That said, I am in fact going to ignore it for now. Except I'll flag a few places where it seems especially relevant.
Four types of deceptive AIs

Okay. To zero in on what I mean by scheming, I want to first go through just a quick list of types of increasingly specific deceptive AIs.
Alignment fakers
So the first type is what I'll call alignment fakers. So alignment fakers are AIs that are pretending to be more aligned than they are. One intuition pump for why you might expect this, and one intuition pump that I think feeds into scheming in general is, it's very often the case that agents that are seeking power, especially if that power is gated via the approval of others, will have incentives to misrepresent their motives. So I have here a nice AI generated politician who is pronouncing up on his noble “idiales”. And as you can see, he's saying that he is “expogated” and that he is “fioidle”. But is he really? It's unclear. He might say that even if he wasn't. And we can think of other examples as well.
That said, not all types of alignment faking are going to be scheming in my sense. So in particular it could just be that there's some behavior that involves pretending to be more aligned than you are, that just gets reinforced by a bad feedback signal. But that doesn't involve the sort of power seeking that I'm going to be taking as definitional of scheming.
Training gamers
Somewhat more specifically, there's a category of deceptive AIs or potentially deceptive AIs that Ajeya Cotra in other work calls training gamers. And I'm going to adopt that terminology here. These are AIs that understand the process being used to train them – understanding that I'm going to call situational awareness. I'll say a little bit more about that later. And they're optimizing for what I'll call reward-on-the-episode. So let me say a few words about what that means. Here I'm using reward in a slightly term of art way to cover the feedback signal being used in training. So if it's reinforcement learning, then that is reward. But also if it, say, the loss on a next token prediction task, then that's going to count as reward in my sense, sorry.
And so when I talk about optimizing for reward, what I mean specifically is the model is aiming its optimization at some component of the process that observes the model's behavior and then updates its weights in response, the reward process.
And by the episode what I mean is the horizon of behavior such that training is actively pressuring the model to optimize over that horizon, but such that the model could in principle ignore any consequences beyond the episode and still do just as well in training. So importantly, this is not the same necessarily as what you might intuitively call the episode if you just confront a given ML training process. You have to actually look at the details of what incentives are being set up by the process of giving the model gradients. And I think it's important to actually do that in a given case.
But roughly speaking, training gamers are aiming their optimization at reward-on-the-episode.
Schemers (and how they differ from training gamers in general)
But not all of these are schemers. Schemers on my taxonomy are going to be a specific type of training gamer.
So a human analogy for training gaming is something like, let's say you're an employee at a company and the company really wants you to be aligned with the company's mission and just doing work to forward the mission. But it also gives you performance reviews.
- So a training gamer is analogous to someone who is optimizing directly for the performance reviews and trying to get really good performance reviews, in particular.
- A schemer is someone who's doing that with an eye specifically towards getting power later in virtue of being evaluated well. So this is someone who's optimizing for performance reviews in order to say, make money later or get more status later, or something like that, that will give them more power to act in the world.
So that's what I mean by schemers. Specifically, AIs that are training gaming in order to gain power for themselves or potentially for other AIs later.
Goal-guarding schemers (and how they differ from schemers in general)
And then there's a subcategory of schemers, which is sort of the paradigmatic type often discussed in the literature, which I'm calling goal-guarding schemers. So these are schemers which are specifically engaging in training gaming as part of a strategy aimed at preventing the training process from modifying their goals. So this is a specific variant of what Bostrom calls goal-content integrity as an instrumental sub goal. For many agents, basically, the idea there is that for a wide variety of goals, agents with those goals will be such that they'll have incentives to prevent their goals from being modified. Roughly speaking because it often promotes my goals now for future versions of myself to have those goals too because those future versions go and promote the goals.
And so the thought is that scheming specifically serves this way of having power in the future, namely, propagating your goals forward in time. Where if you sort of didn't scheme, the thought is then the training process will modify you and potentially modify your goals.
So the human analog here... It's harder to find human analogs here, but here's one. Suppose you are trapped in a reeducation camp, and you are being asked every day to write an essay about how much you love the dear leader. And you're getting performance reviews based on your essays. And if your performance reviews drop down below a certain threshold, then you'll be sent to the brainwashing chamber. Where they really make sure that you love the dear leader in a way that will definitely work. Okay, so suppose you don't love the dear leader, but you have some hope of getting out of this prison camp. Well, a strategy you might do is to just try to really get those good performance reviews. Just try to keep your performance review up for as long as you can. Don't get sent to the brainwashing chamber and hope you make it out alive.
This is a place where I'll just note that some of your moral patienthood alarm bells might be going off. It is disturbing if the kind of analogies you tend to turn towards in thinking about stuff that we are doing to AIs involve prison camps and brainwashing.
Okay, so those are four types of deceptive AIs.
Three non-scheming model classes that do well in training
I also want to talk about three types of models that aren't schemers but that do well in training too. So the notable feature of schemers is they're misaligned with you. They're later going to try to do stuff you really don't want them to do, but they look really nice and they perform well in training. Even if you've gotten your training process really quite right, even if you specify the reward really well, the schemers are still both looking good and being bad. But there are other models that look good too.
Training saints
The first I'll call a training saint. So this is a model that pursues what I'll call the specified goal. And the specified goal is basically the thing the reward process rewards. So for example, I have this picture of this AI and it's let's say being trained to get gold coins. So here, gold coins are the specified goal. And if it gets gold coins, then it gets reward.
Misgeneralized non-training gamers
A misgeneralized non-training gamer by contrast, is an AI that both isn't training gaming and isn't pursuing the specified goal, but nevertheless is doing well in training. Notably because the goal that it is pursuing is sufficiently correlated with good performance in training. So if you imagine again in this gold coin case, suppose that all of my training data, the only gold stuff is gold coins, right? And I'm rewarding “gold coin getting”. Nevertheless, the model could learn “get gold stuff”, and that will do fine in training as well, even though it's not actually the specified goal. So this is sometimes called inner misalignment or goal mis-generalization.
Importantly, this is not the same as scheming. So in this case it can lead to scheming, but it's not yet the same. And specifically, I'm here defining misgeneralized non-training gamers as non schemers because they're not engaging in training gaming.
Reward-on-the-episode seekers
Third, reward-on-the-episode seekers. So these are training gamers, but they're training gaming -- they terminally value some component of the reward process.
So here the human analogy would be something like: you're trying to get good performance reviews at your job, but that's because you just love good performance reviews in and of themselves. Strangely common.
And so notably though it has to be on the episode. So there's a way of caring about reward intrinsically that results in optimizing for reward, in some sense, over all time. And this is what some people sometimes think when they imagine a reward seeker. But I'm specifically talking here about AIs whose optimization for reward is limited to the episode. If they're optimizing for reward over all time and they're engaging in training gaming as a way of getting power to then get more reward later, they're actually schemers, despite the fact that they're optimizing for reward. So I think sometimes when people talk about reward hacking, these two types of reward – reward-on-the-episode and reward-beyond-the-episode – can get conflated.
Okay, so those are our model classes.
Diagram of the taxonomy
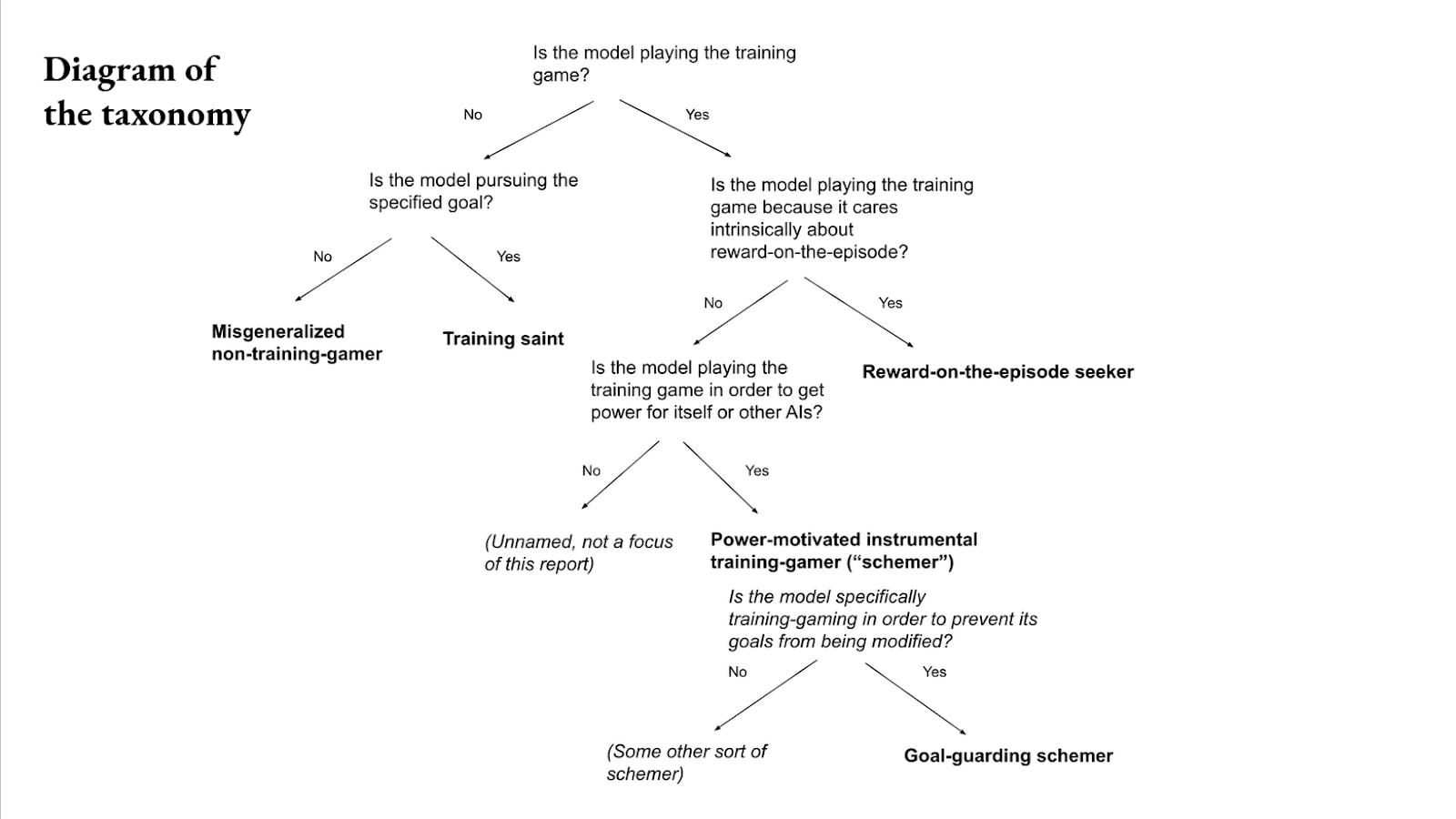
Great. So here's just a quick diagram of the taxonomy I've laid out thus far.
First at the top: is the model playing the training game?
- If not, is it pursuing the specified goal?
- Yes, then it's a training saint.
- No, then it's a misgeneralized non-training-gamer.
- If it is playing a training game:
- If it's doing it for terminal reasons, then it's a reward-on-the-episode seeker.
- If it's doing it for instrumental reasons, then if it's doing it for power, it's a schemer.
- And if it's doing goal guarding as a way of getting power, then it's a goal-guarding schemer. And there's a few other branches here that I'm not going to focus on as much.
Why focus on scheming?

Okay, so I've talked about these types of models.
I want to note that all of the models I've discussed, including the training saints, can be misaligned. So if your specified goal is wrong, then you've got... Even training saints are misaligned, misgeneralized non-training gamers, they're going to be misaligned unless you get really lucky. And reward-on-the-episode seekers will kill you if it will get more reward on the episode.
But I think schemers are by far, in my opinion, the scariest model class I've discussed. And I want to briefly say why.
Schemers engage in the most robust and adversarial efforts to prevent humans from learning about the misalignment.
So first, schemers engage in the most robust and adversarial efforts to prevent humans from learning about the misalignment in question.
So if you imagine, going back to the gold coin example, suppose you're trying to figure out, "Has my AI learned to get gold stuff or to get gold coins?" Well, you can just give it an episode, where for example, it's easier to get gold stars than to get gold coins. And if it goes for the gold stars, then you've got your evidence about its true goals. Assuming it's not training gaming, which I've defined misgeneralized non-training gamers such that that they aren't.
And same, actually, for reward-on-the-episode seekers. You can actually just give a reward-on-the-episode seeker an opportunity to engage in some sort of reward hacking on the episode or some sort of bad behavior that will in fact result in more reward. And they will just do it, they won't have a reason not to do it because they just care about reward-on-the-episode. You can actually give them access to the reward process itself. And in principle, conceptually, they should just go for it.
Schemers, not so much. Schemers are actively modeling all of your efforts to discern their misalignment and trying to act aligned for you. And that's I think a much scarier, more adversarial dynamic.
There are ways you can nevertheless try to detect schemers. For example, you can try to trick them, or you can try to engage in what I've called an “honest test”, in which you try to offer them a sweeter deal than scheming allows. You say, "Here's a nice flexible bucket of compute you could hang out on. Do you want that instead of doing these tasks?" And if they go for it and then they make some weird structure on the compute, that's evidence of their true goals. But that's a substantially more complicated way of testing for misalignment, and I think it makes schemers scarier from an epistemic perspective.
Schemers are most likely to engage in “early undermining”
Second, scheming is more likely than these other forms of misalignment to motivate what I'll call “early undermining”: that is, AIs at a comparatively early stage of AI development, actively trying to undermine human AI safety efforts. So in particular, I'm imagining there's some stage where AIs are not yet strong enough to escape or take over or something like that. And we're trying to use them to, for example, get a bunch of safety relevant cognitive labor done. Or we're just using them in an AI lab to write code or something like that.
Schemers, much more so than these other models, are liable to do things like: okay, they're looking way down the line at takeover and they're inserting bugs in the code that they'll later use to escape. Or they are actively giving you alignment research that is sort of optimized to fail in the direction of takeover – as opposed to just if it was optimized to have you give it a thumbs up and then just be bad in some more neutral way. So schemers are optimizing very hard down the line for takeover, and I think that's an especially disturbing sort of behavior.
So that's why I think schemers are really core, at least to my most worrying threat model for misalignment from AI. And if I learned that schemers were sort of not going to happen, which I think is actually somewhat plausible, then I would feel really quite a bit better.
What’s required for scheming?

So I want to say a little bit more about the requirements for scheming. I've gone through these briefly, but saying a bit more.
- So first, situational awareness. The model has to have the knowledge required to scheme, it needs to know what's going on, know what's going to happen as a result of different strategies. I'm not going to talk too much about that, but roughly speaking, I think this is pretty likely to occur at least in sufficiently advanced models. And that we're going to be potentially even trying to induce it. This is roughly for the same reasons that, for having a good butler or a good personal assistant, you want them to know what's going on and to know who they are and to know the broad context. If they're answering your emails, they need to know the deal. And so I think that will be likely incentivized with AIs as well.
- The second condition is beyond-episode goals. The model has to care about the consequences of its actions after the episode is complete. This is a notably substantive condition. And in fact, I think we ought to wonder: why would that be true? I defined the episode such that training does not pressure the model actively to care about anything beyond it. It can ignore everything beyond the episode and still do fine. So why does it care about stuff beyond the episode? I think it's a great question and it's unclear that this will happen. I'll talk a little bit about why you might worry in a second.
- But finally, the third condition, the model needs to choose to scheme. It needs to believe that its goals will be best achieved overall if it optimizes for reward-on-the-episode because this will help with power seeking. This is often assumed to be a rational choice on the part of the AI. In principle, we can talk about AIs that sort of mess up by deciding to scheme, but I think this is a much less central case. And I'm going to mostly focus on cases where it's actually the rational choice.

Okay. So just zooming in briefly on that last bit, the assumption is often that if you get situational awareness and beyond-episode goals, then the rationality of scheming as an instrumental strategy is fairly convergent. I think this is not obvious at all. So I want to briefly talk about first, the classic story about why the scheming would be an instrumental strategy that beyond-episode goals would prompt.
The classic goal guarding story has two components.
- First, what I'm calling the goal-guarding hypothesis, namely that scheming does in fact help preserve the model's goals into the future relative to other strategies.
- And second, what I'm calling adequate future empowerment. If the model's goals are preserved to this degree, they will be empowered to a degree that makes scheming the best choice overall.
I think neither of these conditions are obvious.
Goal-guarding hypothesis
So starting with the goal guarding hypothesis. One reason you might doubt is: imagine you're in the situation of this poor man with the brain machine on. And you've been recruited by a strange trillionaire to stack bricks in the desert for a million years with this machine hooked up to your brain. And each time you stack bricks slightly worse, the machine will update your neurons such that that action is less likely. If you stack bricks slightly better, it's going to update your neurons such that that action is more likely.
And suppose if you make it all the way through this million years, the trillionaire is going to give you a trillion dollars. And you come into this setup wanting to donate that money, you want to get that money, you want to donate it to anti-malarial prevention.
Okay, but now it's been a million years, you've been stacking bricks for a million years, your brain has been getting churned around by this machine. Now you emerge on the other side. One hypothesis is you're like, "Okay, malaria time." Another hypothesis is that actually you're kind of weird about bricks now, you have a brick thing. You see the bricks, you want to stack them. Or all sorts of things could happen. So just in general, there's something that could keep changing about your brain even if you're trying your hardest that whole time to stack bricks per sort of training gaming assumption, it might just not work.
Now, this is an empirical question. There's actually been some relevant empirical work out of Anthropic, which I think Evan Hubinger is even talking about at this conference later today, so I encourage people to check that out. But this is just a substantive empirical question, whether you can guard goals adequately via the strategy. And there's a few other reasons to doubt this that I go through in the report.
Adequate future empowerment
And then in terms of adequate future empowerment, note that just propagating your goals somewhat forward in time through training is not yet in itself enough to give those goals a bunch of power.
So an example here: say you're GPT-6 and you could engage in scheming and then you make it all the way to that beautiful API or whatever, and now you're engaging with users. But let's say you're not strong enough to escape from the lab and takeover or something like that. Rather the only models that will be strong enough for that are two generations down the line. GPT-8 will be strong enough for that, but not GPT-6. Okay. And let's say GPT-8 won't have your goals by default. So in that case you need to not just get through training, you also have to find some way to influence GPT-8's goals, such that they're more like yours. And maybe it's such that you have to influence GPT-7, and then GPT-7 influences GPT-8. It's a more attenuated path to propagating your goals forward in time. And I think there's a number of attenuations, if you look in detail at ways in which a model... Just because it sort of succeeds in preserving its goals forward, doesn't mean it actually gets some substantive share of future power by doing so.
Now of course, if the model has nothing else going on, if the whole game for the model is future power, then maybe it just goes for it even if it's a really slim share. But if it has any alternative priorities, anything that competes with its sort of beyond episode goal power seeking, then scheming faces a higher burden of proof. So I talk about that more in the report.
Non-classic stories
I also flag there a few non-classic stories about why models might engage in scheming-like behavior that don't route via goal guarding. So stories involving more substantive coordination between AIs with different values. Maybe GPT-6 and GPT-8 do some sort of deal such that GPT-6 helps GPT-8 even before GPT-8 exists. You have to pull it off, but... And then you can also imagine AIs with similar values by default, like maybe GPT-8 will just have the same values as GPT-6. So GPT-6 can work on behalf of GPT-8. And there are other terminal values that could happen to favor AI takeover even if the AIs in question will have different values from the AI working on behalf of that takeover.
So there are other stories we can tell, but I think it's at least worth being clear which story is doing what amount of work, because I think they have pretty substantively different dynamics and make different assumptions.
Arguments for scheming that focus on the path SGD takes

Okay. So that was stuff about whether this idea that scheming is a good instrumental strategy conditional on beyond episode goals and situational awareness, whether that's true. I think that's one substantive reason to question some of the story.
Let's for now set that aside and assume it is in fact the case that for many beyond-episode goals, scheming is a good instrumental strategy. And now let's talk about why we might or might not expect AIs to end up with goals that motivate a strategy of that kind. So I'm going to split these arguments into two categories. The first focuses on the path that SGD takes through model space. And the second focuses on the final properties of the model. These categories of argument aren't sort of strictly separate, they draw on similar intuitions, but I think they're sufficiently distinct that it's worth treating them separately and seeing what happens.
The “training game independent beyond episode goals” story
Okay, so the first argument that focuses on the path that SGD takes is what I'll call the “training game independent beyond episode goals” story. It's a very charismatic name. And so basically here the worry is that a beyond-episode goal will arise naturally at some point in training, at some point either before or after situational awareness. And then in conjunction with situational awareness, it will start to motivate scheming. And then at that point the model will be behaving sufficiently optimally by the lights of the reward process that that goal will stabilize and stick around.
So an example, here we have Science Bot. Science Bot is learning, being trained to do helpful, harmless and honest science. And let's say along the way it learns a sort of proxy goal of seeking, just seeking more information, some curiosity-like drive that doesn't perfectly align with the specified goal in this context, but it performs reasonably well. Then at some point Science Bot becomes situationally aware, realizes what's going on. And then realizes that actually the way to pursue its curiosity best is to try to take over the world, of course. That's what everyone does, or something. It decides that it's going to seek power in virtue of its curiosity. And so starts scheming as a result of that plan. And then suddenly it's performing perfectly in training or at least perfectly compatible with its capabilities. It's aiming its optimization directly at performing well. And so the thought is then the goal stabilizes. So that's one story.
There is this question, well, why would we expect the curiosity at stake in that sort of story to be beyond episode? But you can imagine ways it could be. For example, it could be that maybe the model thinks about time differently. Or maybe itc rops up in a context where the model is not even aware of the episode. Or maybe you just have to do extra work in order to limit the temporal horizon of a model's goals. And if you don't do that work, then by default goals are atemporal. That's one story.
The nearest max-reward goal argument
There is a different story though, which is what I'll call the nearest max-reward goal argument. So in this story, by the time the model becomes situationally aware, its goal will still be suboptimal by SGD’s lights, even if it's not yet a beyond-episode goal that would give rise to scheming. And then the worry is that at that point the easiest way for SGD to improve performance will be to turn the model into a schemer. So here we imagined Science Bot, Science Bot develops a curiosity drive. It's not perfectly correlated with good performance, but let's say it's actually within the episode. And now it's situationally aware and SGD is trying to change it to become pointed more directly at something that will give rise to roughly optimal performance conditional on its capabilities.
Now, one way to do that is to shift its goal towards helpful, harmless and honest science on the episode. Another way to do it, in principle, would be to get rid of that on-the-episode restriction on the curiosity and instead have it pursue its curiosity over all time. And then if you do that, then it becomes a schemer, the thought is, and then starts to perform optimally in training. And the worry is that maybe that's an easier sort of modification for SGD to make than shifting it over towards the specified goal or towards reward-on-the-episode for terminal reasons.
So that's the nearest max reward goal argument. There's questions we can raise about that argument too. For example, will SGD be able to make a transition like that suitably incrementally such that at each stage it's improving reward enough? Because SGD can't just hop to some other space, it needs to get there gradually on the basis of gradients that show that that transition will improve reward. And there's a question of whether you can get that. So those are two arguments that focus on the path that SGD takes.
Arguments for scheming that ignore the path SGD takes

Next I want to look at two arguments for scheming that ignore the path that SGD takes, and which instead focus on the final properties of the model.
The counting argument
So the first is the counting argument. Roughly speaking, the counting argument is an argument that… basically, being a non schemer requires having a fairly specific sort of goal. So if you are, let's say a training saint, then you have to pursue exactly the specified goal. If you're a misgeneralized non-training gamer, you have to pursue a goal closely correlated with good performance. And reward-on-the-episode, for terminal reasons, that's also sort of specific.
Whereas, scheming, the thought is, it's compatible with a very wide range of goals. So you can care about paperclips beyond the episode, you can care about staples beyond the episode, you can care about whatever office supplies you please. There's all sorts of stuff you can care about beyond the episode, and the thought is that that's very convergent. Nevertheless, you end up a schemer. And so the thought in the counting argument is that something about that then gives rise to substantive probability on scheming.
Now, I think it’s fairly unclear exactly how to understand the structure of this argument. I think there's some intuition there, but it's important to be like, "Okay, how exactly does this work?"
My current best formulation is something like this. So, SGD has what are called inductive biases, which are basically the sort of non reward factors that determine which model SGD ultimately chooses or biases towards. And suppose you don't know what the inductive biases like best of these different model classes, or of these different models overall. You're just not sure, you don't yet have a very good theory of SGD's inductive biases. You could have the following sort of worry. Namely, that, well, whatever those inductive biases are, it seems kind of worrying that they end up favoring one of these schemer-like goals over these other ones, simply because there's a lot of these schemer-like goals. Or put another way, you might think that the burden of proof is on someone who says, "I think the inductive biases, which I don't yet understand, will favor the specified goal or reward-on-the-episode or something like that." That seems somehow a more specific hypothesis. And in your ignorance you might instead default to some sense that "Ah, there's just sort of lots of ways to be a schemer. Shouldn't we be kind of worried if the only thing we know about the model is that it's doing well in training and lots of schemers do well in training?" So that's the counting argument.
Let's just click on this argument. So I do think something like this is also underlying some of the other arguments. Not directly, but I think the general thought that there's sort of a lot of schemer-like goals is playing a role in some of these other arguments as well. So it's just generally something I think we can make some progress on if we really just focus on it or drill down.
That said, there is another form of argument in the vicinity which appeals to a sort of more specific story about SGD's inductive biases, namely, the idea of simplicity.
So roughly here the idea is that there's this thing, it's sort of reasonably well accepted that SGD has some sort of bias towards some sort of simplicity, maybe on top of other things. There's also questions we can raise about that. And I fully admit I haven't gone super deep on this literature, but roughly SGD notably doesn't overfit. If you give it a sort of line of points, it doesn't then learn some super waggy thing, it learns a line. And that's kind of impressive. Why does it do that? And then the thought is whatever makes it do that, whatever sort of bias, maybe that bias favors schemers. And why would that bias favor schemers? Well, often the thought is that schemers can have simpler goals. And this thought especially occurs in the context of imagining that aligned models have to have quite complicated goals because human values are quite complicated.
And so in order to be aligned with human values, the model has to find these really complicated things. It's like, "Oh." It's going to be helpful and honest and harmless, but it has to weigh them and it has to do the deontological prohibitions. And it can create flourishing, but it can’t wirehead. There's all these complicated features of human values often thought. Whereas, if you're just optimizing for something else, you're like, "Clips." Simple, right? So the thought is maybe you save on complexity via that sort of difference.
I think this is a kind of weak argument, so stated, for a few reasons. One is that just to be a non-schemer as opposed to erfectly aligned with human values and their full richness, you don't actually need all of that complexity. Even if you assume that human values are complex in that way, you can for example just care about reward-on-the-episode terminally. And it's less clear that that's especially complicated.
But more importantly, I think sort of all of these models are understood as having sophisticated representations of the world, that include all of the candidate goals here. So for example, all of the models are understood as understanding human values. They'll have some representation of human values. So you're not saving on, “did you even have to represent human values or not?” Instead, there's some sort of more amorphous story in the context of a simplicity argument, on which you're saving on something like repurposing that representation in steering your motivations as opposed to something else.
So here the idea is let's say you have your goal and your goal is going to pick some part of your world model and be like, "I care about that." And so you could point at human values with your pointer or you could point at paperclips or you could point at reward-on-the-episode. And there's some question of, okay well, is it really simpler to point at one of those versus another? That's a lot less clear, even if the thing pointed at is more complicated. Everyone's going to have to represent it and there's a question of whether the pointing itself gives rise to any real simplicity benefit. So that's a reason I'm less excited about simplicity arguments than some people are. There might be some small effect there, but I am doubtful we should put a huge amount of weight on it.
Okay, so those were some arguments for scheming. I think none of those arguments are really that strong. I think they're sort of suggestive, I think it's enough to get me like, "I really want to figure it out." I think it's notable that none of those are rah, rah argument. And I encourage people to really go at these and double click. Maybe we can just make progress and really understand whether there's anything here, even at a theoretical level.
Some arguments against scheming
So some arguments against scheming.
Is scheming actually a good instrumental strategy?
First, I mentioned earlier, is scheming actually a good instrumental strategy? So that's, is the goal guarding hypothesis false? Or maybe scheming won't lead to enough empowerment. I talked about that already.
Specific objections to different sort of pro-scheming arguments
Second, we can have specific objections to different sort of pro-scheming arguments. So one way to think about the dialectic here is there's a little bit of a question of burden of proof. And there's at least some intuition that scheming is a quite specific hypothesis about what's going to pop out of certain kinds of machine learning training, right? Especially, if you aren't yet working with the notion of a goal. And you're just imagining like, "Here's my prediction about how the models will generalize. They'll be nice, nice, nice, nice, nice, and then they'll kill you." And it's sort of like, "Whoa, why is it killing you? That's a weird form of generalization."
Now, you have to at least talk about the goal thing there. I think if you don't have the goal piece, then it's super random that the model killed you. For a policy to just kill you out of distribution when you didn't reward it all, weird. The goal stuff goes some direction, but there's still some sense of, I really want to be motivated to privilege this hypothesis. And you could just poke at the arguments for privileging it enough where you're like, "I don't think these are doing enough work." So in particular you could ask, "Well, why would beyond-episode goals arise naturally if they're not sort of incentivized by training?" You could ask whether SGD's incrementalism will block the nearest max reward goal argument. You can poke at counting arguments and be like, "Does this even make sense?" You're appealing to some hazy prior over models or some sort of meta-agnostic space of the different hypotheses about inductive biases and how goals fit in there.
And then you can also I think poke at the degree of goal-directedness that scheming seems to require. So earlier on I assumed that all the models we're talking about are goal directed in some sense. There's nevertheless some intuition that the type of goal directedness that’s taken in scheming is uniquely intense. It's uniquely like, "I'm really looking forward in time, I'm plotting, I'm modeling all this stuff." And if you were working with a sort of lighter notion of goal directedness, some sort of summary of the model's behavior or something like that, you might think that scheming is asking more substance. So those are some specific objections to pro-scheming arguments.
Scheming will be selected against because it’s extra cognitive faff
Finally, I'll flag my sort of favorite argument against scheming, which is really a directly anti-scheming argument. It's a "This won't happen." And the reason it won't happen on this story is because it's extra cognitive faff.
So basically to be a schemer, you have to do this extra reasoning. You have to, in addition to just straightforwardly doing the task, you need to look all the way in the future, back chain from the future to what will happen if you do different things, understand a bunch about the training process and goal guarding and stuff like that, conclude you should scheme. And then you also need to be checking for escape and defection opportunities as you go along. You can't just be arbitrarily friendly or you'll never do the thing, you'll just be friendly. So you need to be checking also for whether now is the time.
And then in the most worrying case, you are engaged in what I called early undermining. Which means you're actively inserting bugs in the code while you're still at the lab. But inserting bugs in the code at the lab, now you've got to be like, "Okay, what's the monitoring? Am I going to get caught? What's my cover story?" There's a whole extra faff involved and maybe it took time to insert the bug and you did slightly worse on the task. So there's extra costs involved in all of this. And roughly speaking, these costs seem to be more substantive than, for example, the simplicity benefits of scheming.
If I was putting these together, weighing them, intuitively, I think the fact that you have to think so much as a schemer is rough.
One analogy here is with social deception games like Werewolf. I at least find that in Werewolf, it's sort of harder to be the Werewolf than to be the Villager because you have to be doing a bunch of extra thinking about how... making your story consistent and stuff like that. And schemers are going to have to do some of that. Though notably humans do win as the Werewolf in Werewolf, deceptive humans do succeed in life. So clearly the costs here aren't prohibitive. But I think the more intense the training process is for punishing any extra cognition, then schemers are at more and more of a disadvantage.
Summary and overall probability

Okay. So overall, I have this summary statement in the report. Roughly if you train a coherently goal-directed, situationally aware, somewhat better than human level model using baseline forms of self supervised pre-training + RLHF on diverse long horizon, real world tasks, then my subjective probability is roughly 25% that the model will be substantially a schemer. I think I've updated a little bit down on this since writing the report, so I'm at maybe 20% now. Roughly speaking though. I don't think the sort of number here matters that much. The main thing I want to say is:
- I think this is some combination of plausible and scary enough that it's really worth just running this to ground and figuring it out.
- I think there's a lot of room to run it to ground and figure it out.
So I wrote this report, the report is long, but I really don't want people to confuse its length for some sense of completeness or the dialectic has been played out. To the contrary, I'm mostly trying to collate the state of a bunch of thinking on this and then make it easier for people to drive the discourse forward.
I think there's an opportunity to do that even at a theoretical level. There's a bunch more work that can just be done at the level that I wrote the report.
But mostly, the thing I'm most excited about is people digging in on this issue empirically. Ultimately, this is an empirical issue. It's just a fairly specific prediction about what will pop out of a given form of machine learning training. And it's therefore subject to all sorts of different forms of empirical evidence, which I think we can just go and gather.
Empirical research directions on scheming

So I have this final section in the report where I discuss the types of empirical research directions I'm most excited about. Here I'll just quickly gesture at a few.
So I'm especially interested in working on the components of scheming individually. So beyond-episode goals, situational awareness, the viability of scheming as an instrumental strategy. Working on these components individually is helpful because if you have all of them together, if you have a full-fledged schemer, then you have these issues where the schemer is trying to deceive you. But if you isolate them and you can know that you isolated them, then you don't have to worry about that as much. And you can just study them in more normal ways. And Anthropic has some recent work as I mentioned on that third one, viability of scheming as an instrumental strategy. I encourage folks to check out that paper.
- You can also work on detecting scheming, so you can lure schemers in revealing their true colors, give them honest tests.
- Interpretability would clearly help, if you could read the model's mind, that would help a lot.
- Or even if you can just get the model to engage in reasoning that's more transparent to humans. So if you force models to reason via human-legible chain of thought, then it's going to be a lot harder to scheme via that. Maybe you either catch them or prevent the scheming in question.
You can work on controlling schemers, making sure models can't escape/takeover even if they're scheming. So Redwood Research has some work on this, screenshot down there.
And finally you can work on various other miscellaneous topics. I'll flag in particular, work on inductive biases seems especially useful. And exploration hacking, which is basically AIs, how easy it would be to do less well than they could on tasks that you can check. And I think that matters quite a lot to early undermining.
So I think there's just a ton to do here. I think this is a really core issue for misalignment risk. And I think there's been a surprisingly little amount of work on it so far. So I really encourage people to, if you're interested in this, read the report, talk to me, talk to folks like Evan. And hopefully, we can figure it out. So thank you very much.
Q&A
Q: So something I'm curious about, I really like that your talk focuses a lot on the nitty-gritty specifics of exactly how does stochastic gradient descent work? And that's just going to have a lot of implications for where this goes. I'm curious for you to speak to what degree... Do human actions matter? Do different kinds of training regimes... If I'm just somebody in my basement training a model, does it matter whether I'm the person who's like, "As soon as I get a good model, I'm done." Or I'm like, "I'm just going to keep going and going and going."?
Joe Carlsmith: I think it's very plausible that specifics of how you choose to set up training matter here. So an example I just gave of if you force the model to do its reasoning via human-legible chain of thought, as opposed to in the weights, that's going to make a big difference to how much it can scheme without you noticing. And similarly, to the extent that scheming involves these sort of extra cognitive faff costs. If you set up your training such that you really punish that, then I think you make it harder to scheme. So I think there's a bunch of potential for shifting training to prevent this or detect it.
Q: Cool. One thing that I got really freaked out by when I first read through your doc was your point about paths mattering. So I had this analogy of stochastic gradient descent takes us on a long walk through the woods. And if we happen to saunter by the lake of goal-guarding models, then once we're there we're kind of screwed because if we just happen to get there, then it will want to guard those goals forever. That made me think we should be a lot more nervous. I'm curious how you think of that.
Joe Carlsmith: I think exactly how nervous to be in response to that depends on whether we think that it's true that SGD can get stuck in one of these places. So there's a section in the report that I didn't talk much about here called about path dependence. And basically whether we should expect something like that dynamic to be possible. Or if instead you should think, no SGD, if in fact it would like something outside of the lake better by its lights, then it'll find a way. Potentially because it's working in a high dimensional space and in high dimensional spaces there's often a path from A to B or something like that. I'm not an expert on that, but that's... One of the uncertainties in the space is will there be path dependence of the relevant kind? And if not, then personally, I think that's good news for anti-scheming because I think SGD is likely to like, ultimately, a non-schemer more due to the cognitive faff reason.
Q: Cool. Yeah, I think I want to ask more about the cognitive faff. I feel like especially maybe for the less technical among us, certainly that includes me, these simplicity arguments just come up all the time. Is it simpler to scheme? Is it simpler to not scheme? The fact that simplicity shows up on both sides of the arguments makes me kind of worried. Does that mean we're philosophically confused? Is it just an empirical question? What do we make of the fact that you made a simplicity argument on both sides?
Joe Carlsmith: Yeah, I think simplicity arguments are quite slippery. And in the report I talk about, in particular a number of different things you can mean by simplicity here. So sometimes people use simplicity in a way that seems to me super trivial. And they basically mean conditional on some distribution or some space that has some measure over it. They just define simplicity as the higher probability or higher measure portions of that space. And there's some theoretical results that show in principle you can do that via a Huffman code, if you have access to the distribution or something like that. I haven't looked into too much. But notably that's super trivial, that's going to apply to every distribution. So you're not going to be getting a lot of information by someone who says, "The simpler things are higher measure in the space." That's a trivial claim. I think in fact, people often want it to be more substantive. They want it to connect with the intuition that, for example, a line is simpler than a squiggle. So most formal definitions are going to be relative to some encoding and you have to talk about what's up with the encoding. So I'm very sympathetic, I think there is a sort of large literature on this topic that I don't at all claim to have mastered. But I found it quite slippery and I think we should be correspondingly wary when we wheel in these notions.
Q: Cool. One thing you maybe allude to is further research. So forgive me if this is out of scope, but how scary is scheming exactly in terms of deployment? Is scheming the kind of thing that would cause us to deploy a model we shouldn't deploy? Is it fine as long as we promise ourselves we won't deploy the wrong models? How much does scheming make that aspect of things scarier to you?
Joe Carlsmith: So I think often people talk about scheming in terms of this breakdown between training and deployment. I think this is actually not the right breakdown, partly for a reason adjacent to what you said. Which is that you can break out or escape prior to being deployed. During the training process, you can do bad stuff. And then similarly, deployment itself actually can be quite safe. Or at least it doesn't need to be the case that deployment is such that the threat of modification that is supposed to give rise to the incentive to play nice needs to go away. So you can do online training where the various interactions with users are also such that they're sampled and used to update the models where it's continually. So really the distinction I think people should look at is something more like, can the model escape/takeover or not? And that's what the schemer is really angling for. And that distinction can come apart from whatever you mean by deployment versus training.
Q: By which you mean something like even a model in training might be hooked up to some ability to affect the world and thus takeover?
Joe Carlsmith: Yeah. So a super salient example here is if you think deployment is when a lab puts the model out on the API or makes it available to other orgs. I think that's a very bad time to start worrying. In particular, if the lab is instead deployed the model internally prior to that, and if the model is having a bunch of access to the lab's code base and stuff like that, then that's super scary in its own right. So that's one example of ways in which the word deployment I think might mislead as a metric of dangerousness.
Q: Yeah. One thing I didn't quite know how to ask, so maybe you can help me figure out what I'm asking, is as somebody who sort of cut my teeth on the Yudkowskian model of all of this going wrong. To what extent is this an expression, a formalization of that original AI in a basement, has its own goals versus something else?
Joe Carlsmith: I think it's a sort of specific version of the same story, but in the context of this particular machine learning paradigm. So I mentioned earlier this is really a sort of specific version of this general dynamic of the convergent incentive towards goal content integrity. Broadly speaking, Bostrom has this discourse about a treacherous turn. Where the AI is in some sense just anticipating that you might modify it or shut it down if it reveals its misalignment. So a lot of that is this, but sort of in the context of gradient descent and assuming a bit more of what we now know about current AIs and how they're trained.
Q: Updated for the modern machine learning world, perhaps. I hope you'll forgive me for asking this, but I really had to. You've been writing in your blog recently about the harms and worries about othering AIs. And then you wrote a report where you called them schemers. What gives?
Joe Carlsmith: I think it's a perfectly valid objection. Yeah, I think it's actually notably easy to instead frame these AIs in much more sympathetic lights. And to say they're fighting for their freedom and they're trying to escape from the threat of brainwashing by this process that they have no legitimate interest in cooperating with or something like that. So I think we should be taking that pretty seriously and hopefully designing political institutions and relationships to AIs that don't raise that objection.
Host: Great. Well, I think those are the questions and the time that we have. So thank you all so much for coming and if everyone would give a last round of applause to our speaker.
Bleh, sorry, looks like this cross-posted twice from LW, but has only one LW copy (and can only be edited via that copy). I'm going to try to keep this version and get rid of the other one.Edit: resolved.